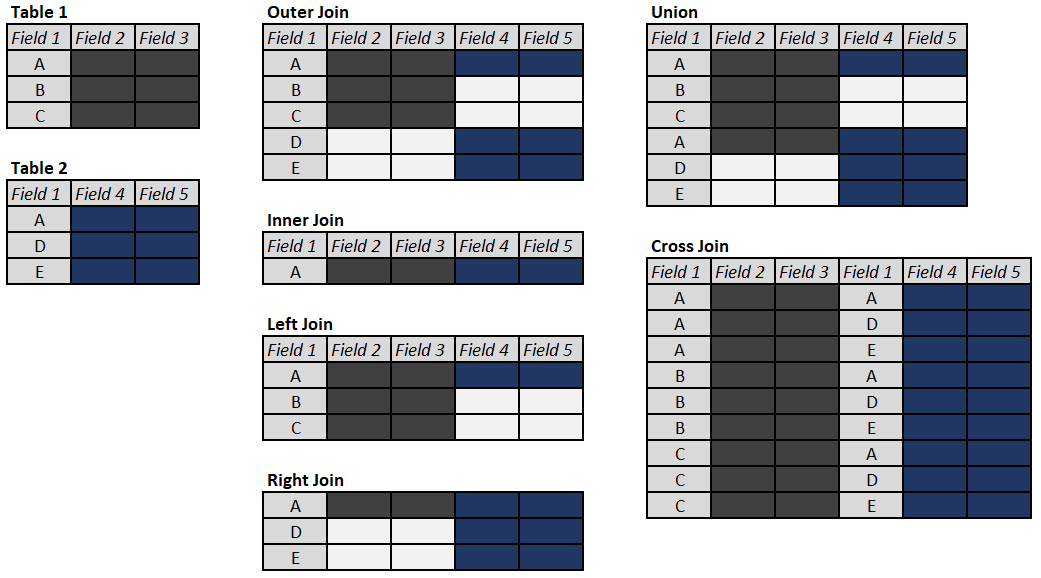
Understanding Table Joins in SQL
Working with data often involves the need to utilize multiple data sources, usually stored in different data tables (in case of database storage) or data frames (when it comes to programming languages or data visualization tools.) In order to put power of this data to a good use we want to be able to join these tables based on a field or fields they have in common (foreign key[s]) or sometimes values in the field that are different. Not only basic principles of table joins – INNER, OUTER (FULL, LEFT, and RIGHT), CROSS (or Cartesian) or even UNION-ing tables are universal to most relational databases and flavors of SQL, they also apply to working with data frames. In this post we will explore examples of using these table joins in a PostgreSQL database, while adding SELF, and LEFT/RIGHT exclusive joins for a good measure.
Continue reading

